creating a model
class MyNeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.first_layer = nn.Linear(4, 6)
self.second_layer = nn.Linear(6, 6)
self.final_layer = nn.Linear(6, 2)
def forward(self, x):
return self.final_layer(self.second_layer(self.first_layer(x)))
model = MyNeuralNetwork()
This code creates this network
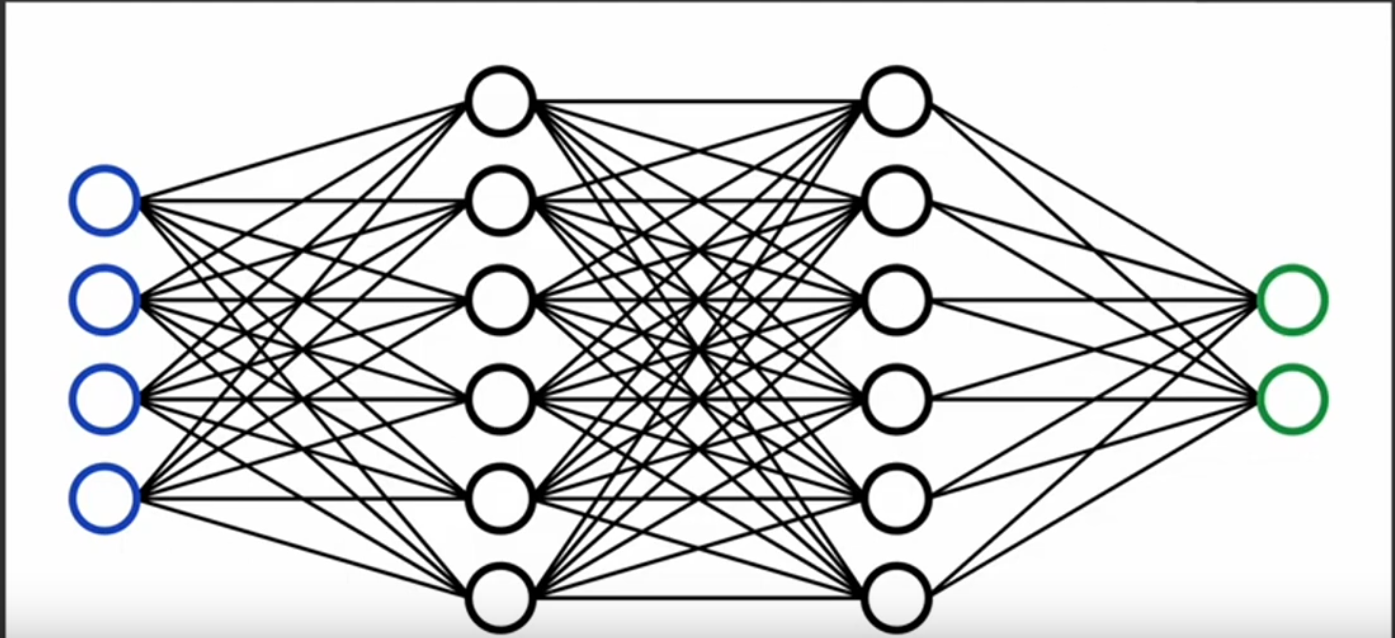
Types of layers
- Linear: Fully connected layer
- Dropoup: Has a probability of dropping completely the node
- ReLU
- Embedding layer: Embedding layer
- Softmax: a relu but normalizes multiple input values and the sum of them will be 1.
Training a model
We need to define a:
- loss function: The function that is going to define our error. When we were doing linear regression we use to use mean squared errors.
- optimizer:
- epochs: Number of passes through the dataset
A sample training loop
model = MyNeuralNetwork()
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
epochs = 5
for epoch in range(epochs):
for images, labels in data_loader:
images = images.view(images.shape[0], 28 * 28) # Load the images and turn them into one dimensional vectors
model_prediction = model(images) # We invoke the model
optimizer.zero_grad() # Reinitializes the derivatives for this iteration
loss = loss_function(model_prediction, labels) # Calculate the loss/error for this predictions
loss.backward() # Calculates the derivatives to perform the gradient descent
optimizer.step() # Updates the weights. Sort of new_w = old_w - derivatives * learning_rate
Loss functions
Mean squared error: For linear regression
Cross entropy loss: For categorization problems
nn.CrossEntropyLoss()
Optimizers
Gradient descent
Adam: Like gradient descent with some extra optimizations
torch.optim.Adam(model.parameters())